







1.数据集结构
文件的结构可以设置成这样:
YOLO_dir
└─ mydata
├─ images
│ ├─ test # 下面放测试集图片
│ ├─ train # 下面放训练集图片
│ └─ val # 下面放验证集图片
└─ labels
├─ test # 下面放测试集标签
├─ train # 下面放训练集标签
├─ val # 下面放验证集标签
比较简单的yaml文件如下(name列表要按照标准的顺序,文件路径是反斜杆):
train: D:/company/py/yolo_dir/mydata/images/train
val: D:/company/py/yolo_dir/mydata/images/val
# Classes
nc: 6 # number of classes
names: ['broccoli','giraffe','potted plant','zebra','people','shoes'] # class namesYOLOv5数可以自动定位标签的位置,原理是吧images替换成labels,因此就按照这样的格式就好了。因此yaml文件不需要指定标签的位置
小规模时,训练集与验证集比例为7:3(或8:2),如果有测试集,则为6:2:2参考
2.通过roboflow生成(官方)
1.1总体流程
标注工具齐全,并且都是在线保存,此外,还可以自动划分数据集、自动生成yaml文件
- 上传文件夹
- 这里推荐这样选择
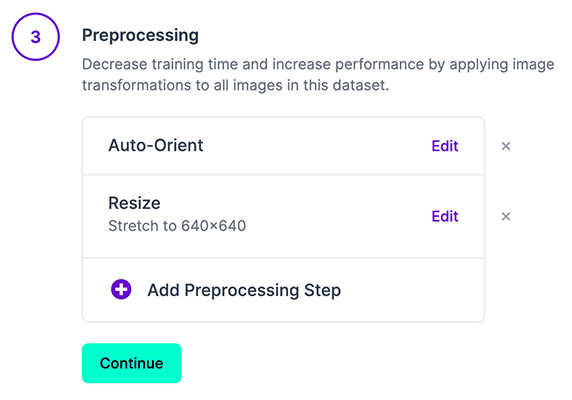
- 不需要做数据增强,因为YOLOv5自带了数据增强
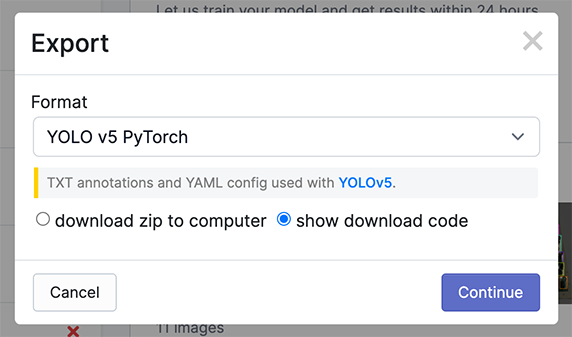
- 导出为YOLOv5格式
1.2 常用快捷键
CTRL--可以切换手与选择框
backspace--连续两次可以把框删除
左右按键--翻页
3.通过labelimg生成
- pip install labelImg安装标注工具
- 在conda环境中直接输入labelImg可以打开
- linxu中lableImg(i要大写)


- 点击pascalvoc,切换成YOLO
- opendir打开需要标注的图像的具体位置
- change save data 确定标注文件夹的位置(路径不要有中文)
- 标注完成后点击保存

可以设置自动保存

4.Tips for Best Training Results
- 先尝试默认的参数进行训练
- 图片数据要足够,官方建议的是超过1500张
- 图像要变化(时间、角度、光线、大小、不同相机等)
- 物体要标注精确,尽量做到boundingbox和物体之间没有间隙
- 增加背景图片(No label),数量大概占据0~10%。这可以降低FALSE POSITIVES(FP)。背景图片的标签文件.txt文空文件,但是文件名要对应。
- 使用YOLO家族大型模型,一是训练慢,二是后面预测慢,但是优点在于精度高
- 默认300epochs,如果发生过拟合了,我可以减少epoch
- 当小目标多的时候,分辨率高训练效果好。因此可以设置--img 1280。如果训练的时候改了--img参数,那么预测也要改
- batch-size应该尽可能大,因为其除了影响训练速度外。如果batch-size太小,会产生不好的batchnorm statistics(BN)














 5238
5238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









